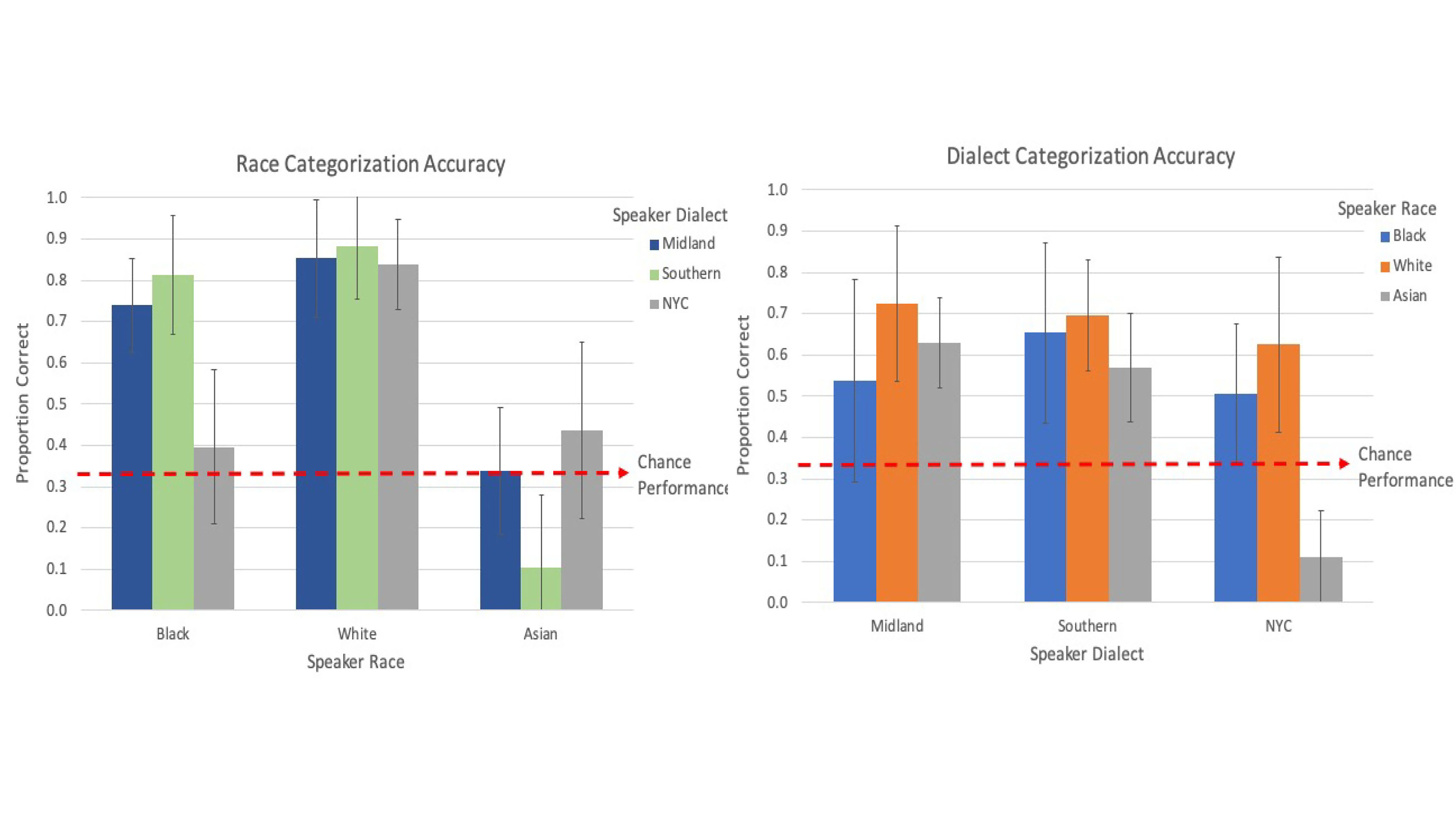
Listeners can extract a lot of information about a person from their acoustic speech signal. During the 179th ASA Meeting, Dec. 7-10, Tessa Bent, Emerson Wolff, and Jennifer Lentz will describe their study in which listeners were told to categorize 144 unique audio clips of monolingual English talkers into Midland, New York City, and Southern U.S. dialect regions, and Asian American, Black/African American, or white speakers.