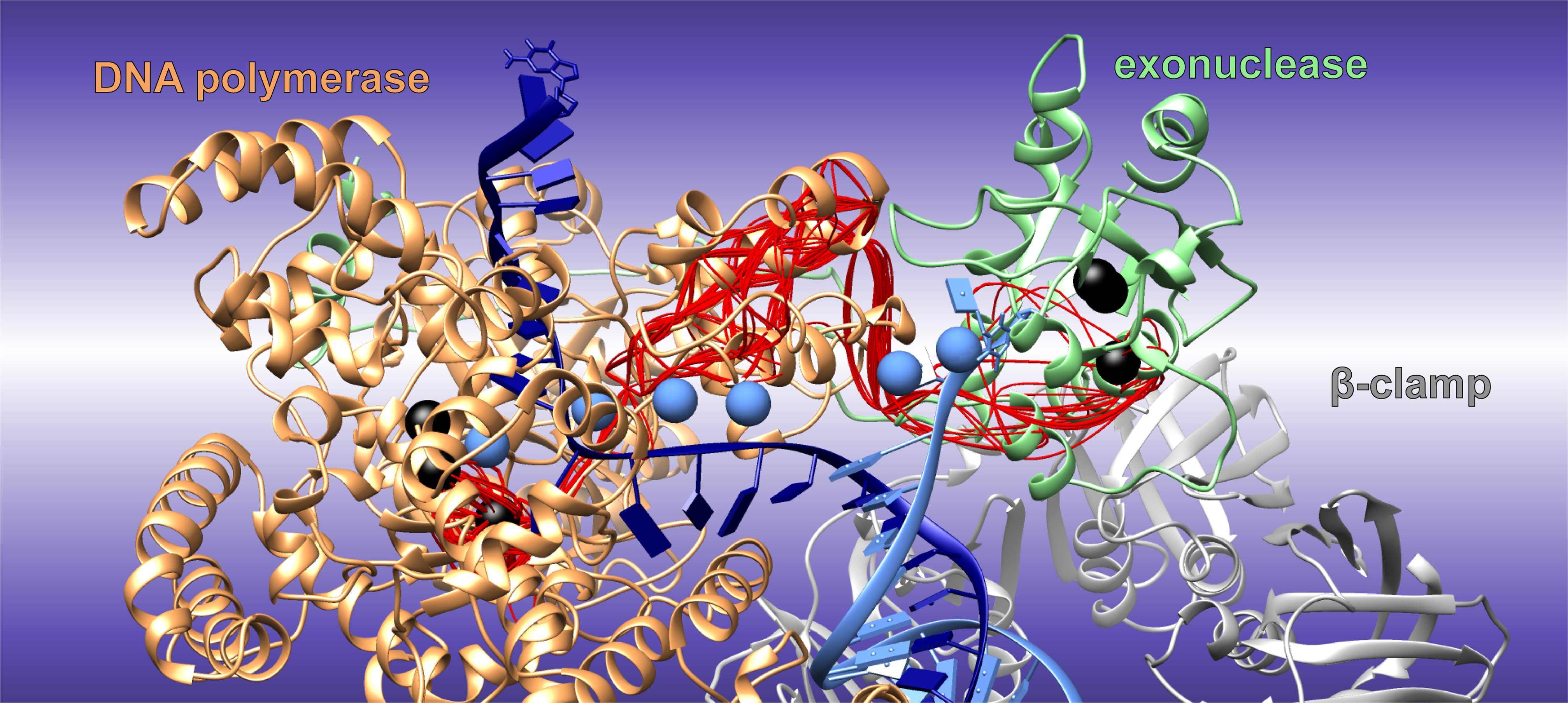
Fortunately, replicative DNA polymerases—the cell’s replication molecular machines—are capable of proofreading the newly synthesized DNA and correcting mistakes made during the DNA replication process. These polymerases detect misincorporated DNA bases and transfer them to a specialized compartment inside of the polymerase to excise them.
If it weren’t for these versatile and efficient machines, the cell’s genetic material would be compromised, potentially leading to abnormal cellular functioning, impaired development, and diseases such as cancer. But just how mistakes are corrected while the polymerase synthesizes a new DNA strand hasn’t been fully understood.
Now, a team at Georgia State University has used the nation’s fastest supercomputer, the IBM AC922 Summit at the US Department of Energy’s (DOE’s) Oak Ridge National Laboratory (ORNL), to find the optimal transition path that a highly accurate bacterial DNA polymerase uses to switch between building and editing DNA. This optimal DNA path serves as a molecular highway, guiding the starting point of the DNA strand as it travels the large distance between the two sites where DNA is synthesized or excised. The work was published in the journal Nature Communications.
“We represented the path between these two—the polymerase and exonuclease states—as a series of replicas of the simulation system that were all optimized and sampled simultaneously,” said Ivaylo Ivanov, researcher at Georgia State University. “Applying path optimization methods to large macromolecular complexes was, until recently, computationally prohibitively expensive. Only with recent advances in GPU technology on massively parallel computing platforms like Summit did it become possible for us to sample the conformational ensemble along the optimal path.”
Because all classes of DNA polymerases have a separation between the polymerase and exonuclease states, the team’s discovery of a defined pathway linking the two active sites suggests that a path between these states is a universal feature of high-fidelity DNA replication, which is essential for safeguarding the integrity of the genome.
Multitasking at the molecular scale
During DNA replication, enzymes—proteins that speed up chemical reactions—called DNA polymerases read existing DNA strands to create new ones, adding DNA building blocks called nucleosides to single strands to create new double-stranded molecules.
High-fidelity DNA polymerases are remarkably precise, introducing a mistake on average only once in a million DNA base incorporations.
“Yet, when you take this in the context of the entire genome, replication could still result in an astronomical number of errors if no correction happens,” Ivanov said.
Luckily, DNA polymerases can identify and correct these rare errors. One such replication machine with a built-in error correction mechanism is DNA polymerase III, or Pol III, from the E. coli bacteria. This polymerase is fast, processive (it can incorporate more than 100,000 nucleotides per binding event), and extremely precise.
Scientists have known that Pol III can switch between its DNA-building and DNA-editing tasks rapidly. They also had structural snapshots of it engaged in DNA synthesis and editing, obtained by cryo-electron microscopy, or cryo-EM—an experimental technique that uses electrons to image proteins in frozen samples. However, images of these two functional states of Pol III did not reveal how the enzyme transitions from one state to the other.
“Accurate and efficient DNA replication requires a delicate balance between continuing DNA synthesis and correcting for errors,” Ivanov said.
It was precisely the origins of this delicate balance that the study aimed to address.
Where computation and experiment meet
Ivanov’s team took advantage of the vast processing power of the Summit supercomputer and employed replica path optimization and extensive molecular dynamics simulations, which reveal detailed movements of atomic structures, to model the process. Using the Nanoscale Molecular Dynamics, or NAMD, code combined with novel data analysis methods, the team elucidated the optimal path for switching between Pol III’s synthesizing and editing states. The computational results were successfully validated in biochemical experiments performed by a research group headed by Professor Meindert Lamers from Leiden University Medical Center in the Netherlands.
The team also used Rhea, a cluster system at the Oak Ridge Leadership Computing Facility (OLCF), to analyze the vast trajectory data collected for all the intermediates stages along the optimal path. These analyses powerfully elucidated the motions and molecular mechanisms of the Pol III replication machinery. They also provided the researchers with a map of its possible states throughout its transition, revealing critical bottlenecks in the transition that serve as go-no-go points, aiding in the discrimination between matched and mismatched DNA.
Using a statistical analysis method called multi-ensemble Markov modeling, the team also determined a complete kinetic model—a description of all elementary steps of the biological mechanism along with the corresponding transition rates—and gained the ability to provide realistic timescales directly comparable to biochemical experiments.
A common thread
While directly relevant for identifying Pol III replication mechanisms, the results of the study can also inform understanding of the function of other classes of DNA polymerases.
“All classes of DNA polymerases feature this remarkably large separation between the active sites responsible for DNA synthesis and DNA editing, suggesting that the concept of a transition path between them is universal,” Ivanov said.
Insights gleaned from these studies hold promise for applications in both biotechnology and biomedicine. Understanding how bacterial polymerases function could help scientists counter bacterial infections, for example.
The team plans to extend the Pol III study to other DNA polymerases and continue exploring this important mechanism. Additionally, the path optimization approach adopted in this study could prove invaluable in modeling structural transitions in other complex biological systems in the future.
“Our combination of cryo-EM structures, advanced molecular dynamics, and biochemical methods demonstrates a multidisciplinary approach that provides novel crucial insights into the mechanics of molecular machines such as the DNA replisome,” Ivanov said. “We look forward to continuing our study of this important mechanism.”
The OLCF is a DOE Office of Science User Facility located at ORNL.
Related Publication: Thomas Dodd, Margherita Botto, Fabian Paul, Rafael Fernandez-Leiro, Meindert H. Lamers, and Ivaylo Ivanov. “Polymerization and Editing Modes of a High-Fidelity DNA Polymerase are Linked by a Well-Defined Path.” Nature Communications 11 (2020): 5379. doi:10.1038/s41467-020-19165-2.

